
In your living RCM offering do you provide models or templates for systems and components typical to the oil and gas industry?
The short answer is yes. Generic templates may be used subject to the following cautionary note.
A pre-packaged FMEA or RCM analysis can contribute to the process as do other forms of technical documentation including piping and instrumentation diagrams, electrical line diagrams, mechanical drawings and maintenance manuals. There is a tendency, however by new RCM analysts, to overrate the ability of templates to reduce analysis time.
RCM analysis is a learning experience. An engineering manager once remarked, after “sitting in” on an RCM analysis session for only 20 minutes, that he gained more understanding of that asset than he had from prior years of meetings, discussions, and reports. This comment is not unusual. The RCM thinking process channels the discussion in the direction of creative yet practical failure management solutions.
If you have a generic RCM or FMEA template, we recommend that you perform an RCM functional analysis at the outset. By all means refer to the generic RCM template as you would drawings, manuals, and other technical documents. In a functional analysis, examine components, and ask “What is it supposed to do?” You will find relevant insights in your functional analysis not present in the template. Conversely, you will find failure modes and effects in the template that do not apply to your operating context. The functional analysis is so important for setting the framework for the remainder of the RCM process.
Allowing the template to drive your RCM analysis process can be a trap. Recall why you wanted to perform RCM analysis in the first place. Most likely it was to set up a “defensible” maintenance plan? If something related to the asset should go terribly wrong, will you be able to confidently defend your analysis and its resulting PM plan? Will you be justified in stating that your best subject matter experts considered all reasonably likely failure modes by methodically applying a proven RCM standard process? Skipping the RCM functional analysis step omits a vital cog in the human mental machinery needed for a thorough understanding of the asset’s maintenance requirements.
When adding information from a template to your RCM analysis pay particular attention to the Effects analysis. The most descriptive of the 7 RCM questions is Question 4 “What happens?”. Q4 unites a failure mode with the asset’s current operating context so that Question 5 “Why does it matter?” may be answered based on the clarity and completeness of the Effects description. Obviously the Effects analysis contained in a generic RCM or FMEA template will necessarily exclude vital details specific to your organization’s operating contexts.
To resume, templates are a legitimate information source for RCM analysis. However, they cannot replace the RCM thought process. But are there ways to truly save time when conducting RCM? At least two obstacles can slow down an RCM analysis:
- Unnecessary detail[1] and/or depth, and
- Missing information
A commercial template cannot anticipate the depth of analysis or the amount of detail appropriate to your organization. Consequently the template will tend to overload on detail and delve deeper than needed, increasing the time required for analysis. In other words, the result may be opposite to what you intended by using the template in the first place. To speed up the analysis, the RCM facilitator consciously guides the analysis along a narrow path between too much and too little detail. Some failure modes merit greater depth and / or more detail depending on their consequences and likelihood. The RCM Q&A process helps the facilitator elicit an optimal balance of detail and risk resulting in a speedy yet responsible analysis.
The Mesh™ Living RCM (LRCM) process overcomes both difficulties mentioned above by recognizing that the initial RCM analysis is a first approximation of reality. RCM compiles and structures the best information, recollection, and understanding available to the SMEs at the moment of analysis. Subsequently, within the ongoing work order process, maintainers will use the LRCM feedback system to improve the analysis and its resulting maintenance plan. Specifically, the integrated LRCM work order form allows technicians to:
- Suggest a more appropriate level of analysis, failure mode causality depth, 0r amount of detail
- Suggest additions, removals, or changes to answers to the 7 RCM questions
- Gather information for “age exploration”
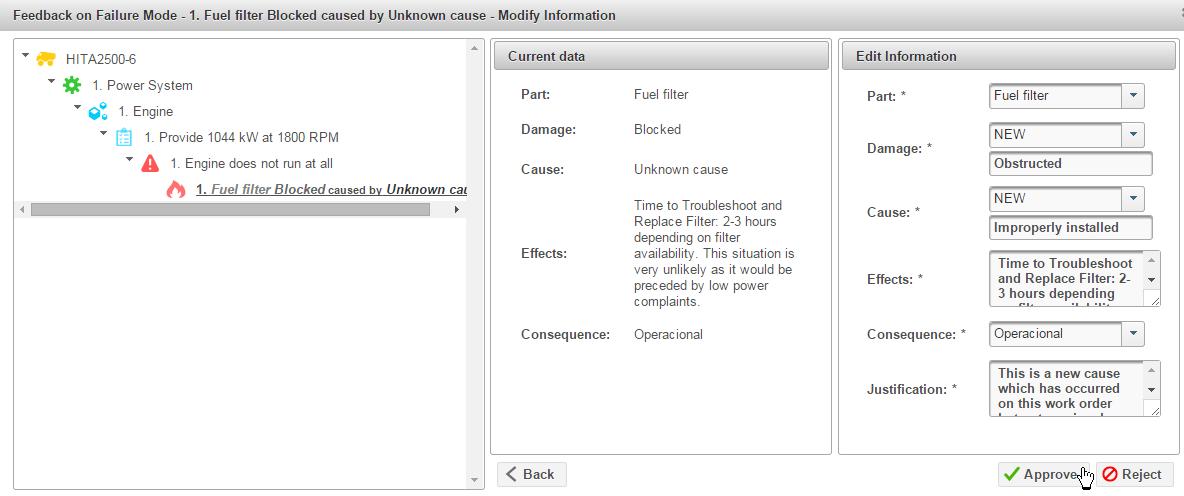
An example of the feedback user interface
Item 3 above requires elucidation. Sometimes, during initial RCM, required information is missing or imprecise. For example, the analysts may have no reasonable estimate of the reliability of an object part or its condition based behavior. In such cases RCM analysts will tend to err on the safe side by opting for a more conservative PM task and / or task frequency. Without a process for continuous review of the RCM knowledge base the maintenance plan will remain sub-optimal indefinitely. Fortunately, LRCM provides an additional tool for carrying out a process which Nowlan and Heap referred to as “age exploration”.
Information gathering (i.e. age exploration) instructions related to a failure mode may be included in the mitigation task(s). When a technician executes a work order related to the failure mode the LRCM procedure will trigger a relevant age exploration task.[2] Additionally, the LRCM work order form displays a running reliability analysis (MTBF) for each failure mode in the RCM tree view, alerting technicians and engineers to anomalous failure behavior. Finally, LRCM provides the means for regular review of new observations flagged by the technician via the feedback system.
Knowing that the analysis will be revisited continuously during the course of normal work order activities RCM analysts will waste less valuable time whenever facts are lacking or uncertain during the initial analysis. Thus living RCM can be an effective time saver. As new information and insights come to light through living RCM the reliability engineer uses the LRCM Feedback Manager module to continuously receive suggestions from the technicians and others to improve the RCM knowledge base.
© 2015 – 2016, Murray Wiseman. All rights reserved.
- [1]Detail = how many failure modes to include. Depth = asset hierarchical level at which to perform the functional analysis. Depth also refers to the populating of the “object damage” and “failure cause” segments of the failure mode description. Sometimes the object damage can be “fails” and the failure cause can be left out entirely when this information provides no added values relative to our operating context. For example, if a PCB is swapped out and discarded and the failure frequency is not excessive, the causality (i.e. which chip failed) is undesired information. ↩
- [2]In particular, the use of the Mesh image gallery function wherein a failure mode may have a unique set of images that assist in establishing standard definitions for failure, potential failure, and suspension.↩
Interesting article Murray. We had two mechanics in today reviewing a pump tear down they had done and they were very engaged in the discussion of how to align what they found with the failure codes in the system. It was a very worthwhile exercise that raised some new questions in my mind around the mechanics of how we are actually going to extract the age data once we get some data points established.
Additionally the question had arisen in my mind about how we record PF that we choose to leave in service. We obviously want to record the observation but we do not want to skew the age data by creating confusion about what was done with the failure mode.
There is also the question of how to record the situation in which there are 6 cylinders on a pump with two valves per cylinder where each of the seats is found worn and needs to be replaced. Do we record the end of life six times ( one for each cylinder)?
These are getting into some pretty low-level details but this is what we need to understand as we start to try and train field staff. We need to understand how we will extract data.
Great points you make. They strike at the heart of the maintenance information challenge, which is to know how much detail and how much depth we need. The pump cylinders and valves are a super example for discussion. Does it pay to define a distinct failure mode for each valve on each cylinder? Or should we group it all in one failure mode “cylinder valve failure”? Or some level of detail in between?
A) the organizational context, B) the business context, and C) the maintenance (CBM) context determine the level of detail you need. Management volunteers A and B. The technical people illuminate C. If necessary a “facilitator” smooths the path to consensus. This subject is not trivial. The maintenance organization that develops the skill to recognize the level and depth appropriate to a variety of situations related to operating context will ultimately achieve reliability from data.
Your question about the PF that was not immediately renewed is an advanced one that needs due consideration. I might slice the bread by treating it as a “non-failure” (by definition) so that it continues to log time. (You would have a note on the work order saying it was a “borderline” PF). Alternatively you could declare it a potential failure but subject to the proviso described in advantage 1 below.
I see two advantages in this way of doing it:
1. You’re applying a consistent rule. There may be a lot of wear but the prognosis for functional failure was “indefinite”. Had you replaced it, it would have been a “suspension” or “potential failure” depending on your organization’s standards. But you kept it in service. By definition, this was neither a failure nor a suspension. It was “non-failed”. On the subsequent intervention where it will be replaced, at that time, it will be recorded as either a “S”, “PF”, or “FF”. Alternatively, it can be recorded as a “PF” on the first work order. But then on the second work order where it is actually replaced, it can be recorded as “S” even if there was further damage since we will have already accounted for the failure. Since the ending event type is recorded as “S”, software such as EXAKT will not be fooled into correlating age and condition data with failure on the second work order. Either of these approaches will enable the software to take on the responsibility for correctly calculating (modeling) failure probabilities for when failure (PF or FF) will ultimately occur.
2. You continuously hone your company’s standards for defining PF and S. (That’s the purpose of a failure mode’s image gallery.)