
When performing RCM how should we handle “common cause failures”? A common cause failure has the same failure mode in common with another failure elsewhere in the hierarchy tree view of the RCM knowledge base. Their appear to be four seemingly similar cases that need to be distinguished, but only case 2 describes a common cause failure scenario.
1. Identical “looking” failure modes: Two failure modes look identical (identically spelled object part, object damage, failure cause), but are different. Their consequences and mitigating tasks are different. Their mitigating tasks should appear separately on the PM schedules. The RCM dashboard[1] for generating the PM schedules, by default, counts and displays each of these identically looking failure modes and their mitigating tasks appropriately as distinct.
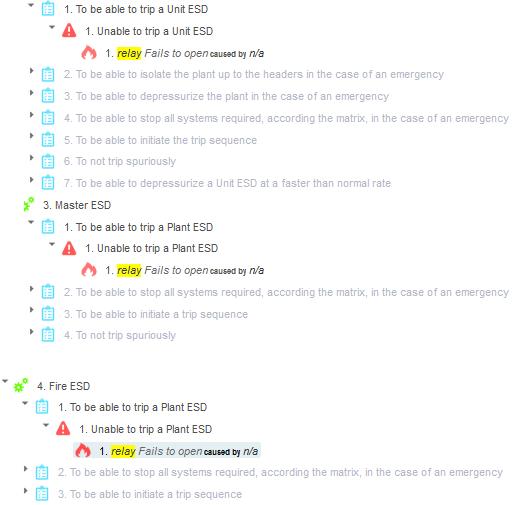 Here is an example of 3 different failures appearing at different locations throughout the analysis. Their failure modes appear to be identical, “Relay fails to open”. But they are different relays located in different parts of the overall system.
Here is an example of 3 different failures appearing at different locations throughout the analysis. Their failure modes appear to be identical, “Relay fails to open”. But they are different relays located in different parts of the overall system.
2. The same failure mode appears multiple times: Two failure modes appear in different branches of the tree, but they are in fact the same failure mode. That is a single failure mode can cause two (or more) failures in different areas of the asset. The technical term sometimes used for this situation is “Common cause failures”. In this case a single set of mitigating tasks will cover all appearances of the failure mode. In the case of common cause failures, we believe the following approach could be the simplest and clearest.
- Whenever the SMEs enter a mitigating task for a failure mode that has already been handled they should place a code, for example “{cc}” in the text of the corrective task. The dashboard will, in this case, not duplicate the failure mode nor its mitigating tasks.
3. The same task handles the consequences of multiple failure modes: It often happens that the same task appears in several places. Executing it one time at the interval determined will mitigate the consequences of various failure modes in the hierarchy. Therefore we do not want the task to be repeated in the maintenance schedule. In this scenario the SME analysts should include in the text of subsequent appearances of the mitigating task the code “{dup}” to indicate that the task has already been entered elsewhere in the hierarchy.[2]
 Assume a single mitigating task appearing, say 3 times, but performed once will adequately reduce the risk associated with all three failures. Obviously we do not wish to repeat the task 3 times in the EAM generated maintenance schedule. This proposed approach will ensure that the task, entered 3 times in Mesh, will appear only once in the maintenance schedule.
Assume a single mitigating task appearing, say 3 times, but performed once will adequately reduce the risk associated with all three failures. Obviously we do not wish to repeat the task 3 times in the EAM generated maintenance schedule. This proposed approach will ensure that the task, entered 3 times in Mesh, will appear only once in the maintenance schedule.
4. Tasks for different failure modes are performed at the same time by the same person(s): A task under one failure mode will be done together with a task elsewhere in the asset tree. An example would be a system which has four similar subsystems (as in case 1) whose maintenance is carried out all together annually by a contractor. The four individual tasks in the different subsystems will be performed efficiently by the same contractor team and at the same time.
- When first considering this, one might request that these tasks be assembled into a single task or task group rather than appear as separate tasks in the dashboard, and subsequently in the Excel maintenance schedules generated from the dashboard.
- This would not be the best approach. Given that the dashboard itself groups the tasks by filtered selection of Asset/Frequency/Skill, These individual tasks will naturally be grouped together on one (annual) task sheet. The list generated for the contractor will have the four tasks individually listed with their own checkboxes (along with the name of their respective subsystems – e.g. unit, plant, master, fire ). At his discretion he would execute them all at once and check them off as they are completed.
- This scheme would give the maintenance department greater control over the work done by a contractor.
© 2016, Murray Wiseman. All rights reserved.
- [1]This refers to the Mesh LRCM dashboard that uses filters for Equipment, Task frequency, and Task skill to generate the maintenance schedules for upload to the EAM. ↩
- [2]Re case 3, Mike has pointed out that a change might be made whereby the first failure mode whose consequences are handled by a task’s first appearance might be eliminated. For example, the failure mode may be designed out, in which case the duplicates of the tasks would be orphaned. They would never appear on the maintenance schedules generated by the dashboard. To avoid this the SMEs or the facilitator could mark the first task appearance with, for example “{masterdup}”. If, in the future, anyone eliminates that task, he will know that there is at least one duplicate elsewhere in the tree**, one of which should then have its “{dup}” code replaced by “{masterdup}” in its text description.↩
[…] code “{gen}” in the Effects text (similarly to the method proposed in the article on common cause failures). The dashboard’s extraction and transformation loading program will skip the general failure […]